
简述
本篇主要是关于一些 核心的名词解释。
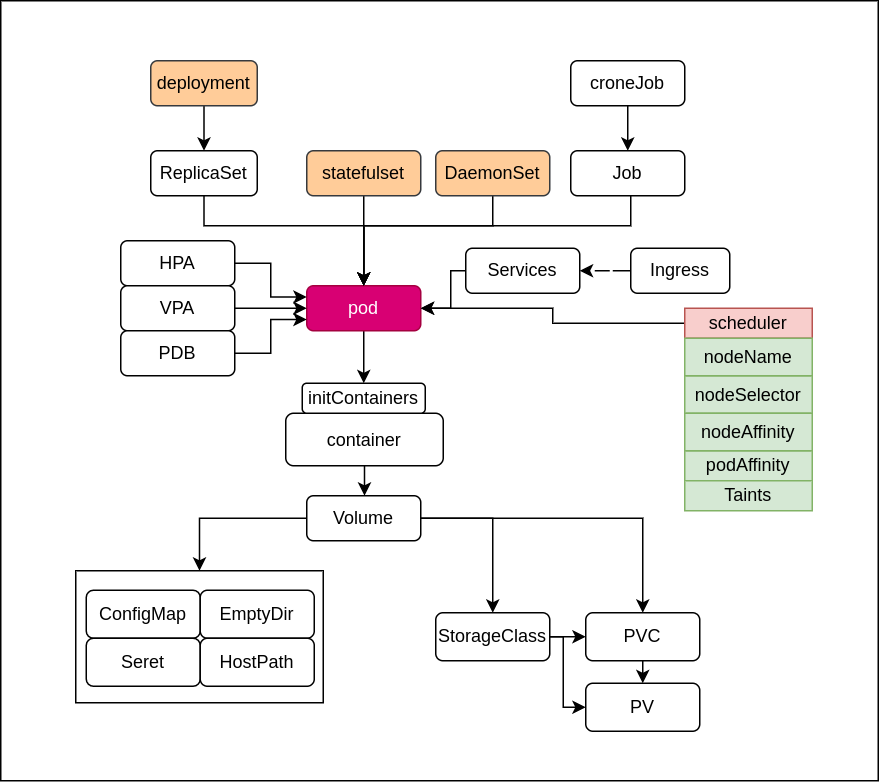
这里有一张我画的 k8s 核心架构图, 只包含最常见的应用类的组件。
不包括物理组件,第三方组件,和自身的一些不常用的细节或控制器。
基础名词
containers 容器
简单理解就是一个被隔离的应用程序。
推荐是一个容器运行一个不可再拆分的进程。
但也不是强制要求,也可以走胖容器的路线,一个容器内跑多个进程也可以。
如果是传统架构迁移过来时,或者多程序之间关联极为耦合,可以临时用胖容器过度一下,后期最好还是单一进程合适。
为什么推荐单一进程呢?目的是增加资源利用率和细化控制。
设想以下场景
- 如果一个容器内有3个进程,1忙2闲。现在因为这个忙的进程资源使用率很高,需要将容器增加2份。就导致2个闲的进程也跟着被扩了2份,不合理。
- 容器因为主进程的需要被授予了A权限,但容器内的其它进程并不需要这个权限。
- 容器内多个进程都向标准输出吐了日志,如何区分是谁的?
POD
理解为一个最小调度单元。
例子1: A 程序向某个 unix socket 文件发送数据,B程序读取此 socket 文件。这就决定了2个进程必须在同一个机器上运行,且必须同等份数的扩容、缩减,以及同时启停等。
所以需要视为一个整体来进行调度。
例子2:多个程序都是使用的 127.0.0.1 来进行相互通信的, 如果调度到不同节点则无法进行通信,即便在同一个节点还不能隔离它们的网络。
所以它们之间需要共享网络栈。
services 服务
当一个类型的应用程序启动了多份之后, 如何使用一个入口访问到全部服务呢?
传统方法就是配置一个负载均衡,如 nginx, HAproxy, lvs 等。
k8s体系内也提供了的负载均衡能力,早期 Userspace 的 kube-proxy + iptable 模式,中期的 iptables 模式,目前主流的 lvs 模式,再如今推荐的 ebpf 模式, 都是来解决这个问题的。
达到一个效果, 客户端访问集群ip和端口,将负载分配到后端的多个pod端口去。
通常使用服务名字来解析出集群IP来使用。
Ingress
Ingress 的主要用途是处理南北向流量,就是外部进入集群时的请求,因为外部一般来说是访问不到集群IP地址的,所以需要单独的一个服务来承载入口。并附带了一个高级功能,如 通用负载算法,ssl证书, 前缀或正则路由等。
说明
Ingress 本身是对负载均衡功能的一个抽象,理解为一套标准。
Ingress控制器, 则是对这套标准的一个具体实现,也就是具体承载入口流量的那个应用程序。
常用的控制器
nginx 生态好, 性能好,文档丰富, 主流, 配合lua插件;
Traefik 非常适合 k8s 环境,自动化程度很高,配合go插件,个人主推;
envoy 据说是性能最好的,配合lua插件, 我使用过,没有自己搭过;
APISix 新出不久,本质还是 nginx+lua, 只是更贴合k8s环境一些。
我目前是主要生产环境用 nginx, 非核心环境用 Traefik, 预研和学习和下一步 envoy。
存储相关
configmap
理解为将 应用程序的配置文件给 apiserver 进行集中存储,然后挂载到 容器内进行使用
注意: 修改 cm 后,需要10-20s 容器内的配置文件才会更新
secret
一般来说就是存放 帐号密码,证书,认证信息等关键私密信息的。
和 configmap 本质没有区别, 单独取个名字 估计只是让用户好区分而已。
emptyDir
临时目录, 用于同一个 pod 内的多个容器之间共享文件系统目录的。
非持久化,pod 关闭后数据清除。
有个特性: 可以使用内存文件系统
HostPath
挂载宿主机上的文件系统目录到容器内使用的方式。
pvc
对存储资源的一种抽象;
存储管理员 将实际的多个存储各取一个名字, 然后标识这个存储的元数据(空间大小,读写特性等),每个存储就是一个 pv 了;
业务管理员在创建 pod 时, 写一个清单,表明我这个程序所需要的存储元数据, 这个需求清单即 PVC;
pvc 创建后会自动绑定空闲的 pv, 绑定成功后, pod 既可以正常使用存储了。
问题: 多个 pod 使用同一个 pvc(需求清单) 时如何绑定 pv 呢?
实际上每个 pod 都会拿着在这个 pvc(需求清单) 去新建一个 pvc 实例, 这个 pvc 实例才是真正绑定的存储。
StorageClass
原来的 pvc 模式需要存储管理员提前把 pv 都创建好, 才能在使用 pvc 时自动绑定上;
可是业务系统需要多少个 pv, 需要哪些大小和类型的 pv 都不是一开始就能定下来的。
所以需要有一种机制按需创建 pv,这也就是 StorageClass 的作用了;
同 Ingress 和 Ingress控制器类似,
StorageClass 也只是一套标准,具体如何创建 pv, 还得由具体的控制器去实现, 这里的控制器就叫做 provisioner 供应商,这个 provisioner 也是一个单独的 pod。
例如创建 ceph rbd, cephFS 的 ceph provisioner, 创建 nfs 空间的 provisioner,创建 oss 的provisioner,创建 gfs 的 provisioner,基本上每一个不同类型的物理存储类型,都需要一个 provisioner。
发布相关
ReplicaSet
ReplicaSet 这个单词我理解为 版本。
比如 目前运行的 10 个相同的 pod 就归为一个版本 ReplicaSet,
但对涉及这10个 pod 的任何变更都会产生一个新的版本。
例如增加了 2 个实例,或者更换了镜像版本, 则新增一个版本。
如果需要回退,则切换版本即可。
滚动升级的原理也是靠 新旧2个版本依次替换实现的。
一般来说除了回滚时,用户也不需要管它。
deployment
主要针对无状态服务,即 pod 自身不存储下次启动所需要的数据这类程序,最常用的类型。
可以随时扩容缩容的pod,例如 nginx, 就只需要 程序二进制文件本身 + 存储在 configmap 内的配置文件,这就是典型的无状态服务。
StatefulSet
针对有状态服务,什么是有状态呢?
- 启动后外部传入进来配置或数据,并存储到了 Pod 本地, 下次启动还需要它。
- 这个服务的 ip和端口外部是固定的配置,服务迁移或重建后 ip 不能变。
非常典型的如 mysql, 不可能每次启动都是空库吧,不可能每次启动都需要客户端更新IP吧,扩容节点后新节点没数据怎么办,有文件锁不能使用共享文件系统只能单点使用这些问题。
思考: mysql 能否做成无状态服务
当然也可以的,但场景非常受限制
无状态读: N个只读数据库, 共享一份只读文件系统,可以随意扩缩容,客户端使用服务名轮询负载各pod, 无数据冲突或不一致性问题。
无状态写:N个只写数据库, 各自独立使用一份块存储, 相同表结构; 只写不读的场景就无数据冲突,定期将N份数据库的内容单独查出来汇总。
有读有写:固定只有一个 pod 的 deployment
DaemonSet
每个 Node 节点都 有且只有 一个的 pod;
一般为监控, 日志采集, 网络或存储插件等特殊的容器,
HPA
水平扩缩容
一般是根据实例的CPU或内存等资源使用量来决定扩容或缩容;
也可以定时触发,或根据其它自定义条件来触发。
VPA
纵向扩缩容
其实也就是调整单个 pod 的资源限制大小
PDB
实例数量的保证,避免更新升级或者迁移时一下关停了太多的实例
保障某服务, 最多不可用 或 最少必须可用 的 pod 数量
scheduler 调度相关
即决定这个 pod 应该去哪个节点上运行
nodeName
最高优先级的策略,点名这个 pod 去哪个节点运行
nodeSelector
选择去哪些节点上运行,可以使用标签选择器 或 名字选择器等多种选择方式。
Taints
污点调度
即给一些 Node 做个标记, 默认不运行其它 pod 过来运行, 除非这个 pod 显式声明自己可以接受这个标记。
nodeAffinity
节点 亲和性, 优先去这些节点上运行
podAffinity
POD 亲和性, 优先去运行有这些 pod 的 Node 上运行。